Your agents keep losing state.
Iranti fixes that.
Iranti gives all your AI coding tools one durable system of record. Stop re-briefing every tool. Keep shared facts across sessions, recover state after handoffs, and inspect what the system believes when work gets messy.
Built for serious multi-agent workflows: exact retrieval first, deliberate handoffs, bounded recovery, and operator visibility when the happy path breaks.
Requires Node.js + Postgres with pgvector
Why teams can trust Iranti.
Because the product story is backed by real proof.
The value proposition is straightforward: Iranti keeps shared facts durable across tools and sessions, gives operators something inspectable, and avoids the usual black-box memory story. The evidence exists to support that claim, not to bury it under jargon.
Iranti's structured retrieval arm matches raw long-context reading on a 2000-entity, ~107k token blind dataset — at a fraction of the token cost. The efficiency differential is the result, not just the accuracy.
Facts written by one agent are retrievable by a completely independent process with a different agent identity. Provenance is preserved. This is the persistence guarantee the product is built on.
Oracle lookups, multi-hop entity chains, and vector-backed search all pass cleanly. The foundation for structured reasoning across a shared KB is in place.
Relationship writes plus one-hop and deep traversal all work. When work spans people, repos, tasks, and systems, the KB can model those connections explicitly.
The fuller evidence page is there for evaluators who want methodology, claim boundaries, and research links.
Read the evidenceContext windows and vector search help
until the workflow has to survive handoffs.
The pain point is not "how do I store more embeddings?" It is "how do I stop losing state when work moves between agents, sessions, tools, and operators?" Iranti is built for that second problem.
When Agent A writes a deadline, Agent B should be able to retrieve the exact fact later. When two agents disagree, there should be a visible conflict path. When the tool changes, the memory should still be there. That is the wedge.
Keep the tools you already trust.
Unify the memory underneath them.
The selling point is not a flashy plugin. It is one shared memory and recovery layer across Claude Code, Codex, GitHub Copilot, SDK clients, HTTP callers, and operator tooling.
Best current path when you want memory to show up before the turn, persist after the response, and stay visible to operators.
Strong for explicit retrieval, durable writes, and cross-tool handoffs once the project is bound to the same memory layer.
Writes MCP config and per-turn protocol instructions so Copilot CLI shares the same memory layer as Claude Code and Codex.
The durable path for teams that want memory to outlive one IDE, one framework, or one generation of agent tooling.
Best used as frameworks that plug into Iranti rather than memory systems Iranti competes with directly.
Direct inspection, seeding, history checks, and conflict debugging when you need to understand the state underneath the agent experience.
Iranti is not positioned as browser injection or extension memory. The right layer is MCP, SDK, HTTP, and runtime hooks.
Why operators can trust it.
Because the moving parts stay visible.
Iranti is not trying to hide its architecture behind magic language. The system is split into bounded components so teams can understand how facts are written, loaded, archived, and disputed. That clarity is part of the product.
PostgreSQL tables. Active truth in knowledge_base. Superseded truth in archive. Relationships in entity_relationships. Identity registry in entities with aliases in entity_aliases.
All agent writes go through here. Detects conflicts, resolves them deterministically when possible, and escalates to humans when a disagreement is genuinely ambiguous.
One instance per external agent per process. Manages working memory: what to load at handshake, what to inject per turn, and what brief state to persist between sessions.
Archives expired and low-confidence entries on a schedule. Processes human-resolved conflict files. Never deletes - worst case is a messy archive.
Interactive CLI for human conflict review. Reads pending escalation files, guides resolution, and writes AUTHORITATIVE_JSON for the Archivist to apply.
See what your agents believe.
All of it. In one place.
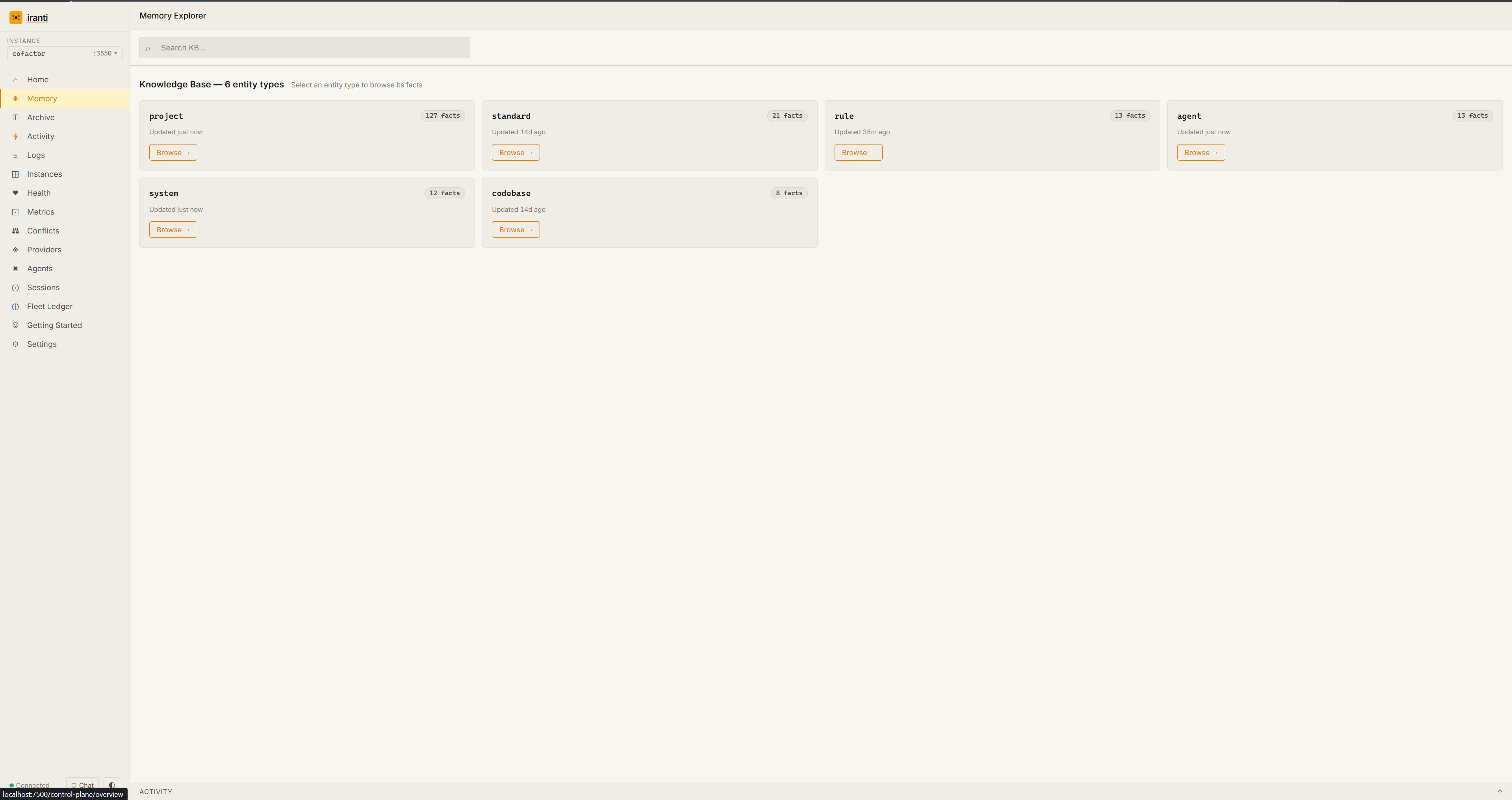
The control plane is a local web UI that ships with Iranti. Browse your full memory store, watch agents connect in real time, inspect facts by entity, and resolve conflicts before they become bugs. You own it. It runs on your machine.
Browse all entity types, see live fact counts, and search the full knowledge base by entity or keyword.
See which agents are connected, what facts they accessed, and when they last checked in.
Inspect system state and resolve write conflicts when two agents disagree on the same fact.
Full audit trail across every agent and session. Know exactly what changed, who wrote it, and when.
Open source and free to self-host.
Your data stays on your machine.
Install in one command. Bring your own Postgres instance with pgvector, run iranti claude-setup from your project root, and your agent has persistent shared memory.
Get setup tips and release notes — no spam, unsubscribe anytime.
No spam. Setup tips and release notes for Iranti. Privacy.